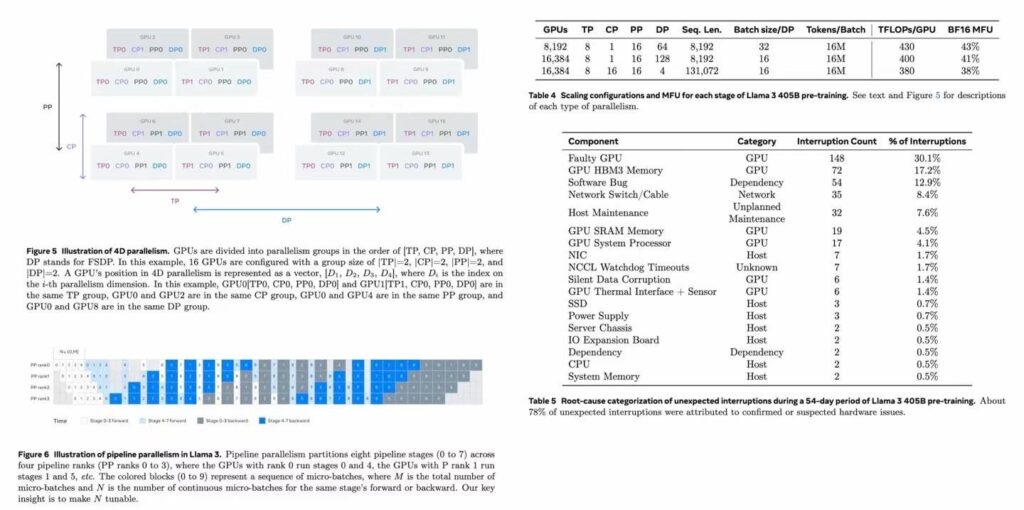
The exponential growth in scale and complexity of large language models (LLMs) has pushed AI infrastructure to its limits. The recent pre-training of the Llama 3.1 405B model offers unprecedented insights into the challenges of extreme-scale AI training. Over a 54-day period, the system encountered 417 unexpected interruptions, revealing critical technical bottlenecks and potential optimization pathways that could reshape the future of AI infrastructure.
Hardware Resilience: The Achilles’ Heel of AI Training
Hardware-related issues emerged as the primary culprit, accounting for 55.9% of all interruptions. GPU failures (30.1%) and GPU HBM3 memory issues (17.2%) stood out prominently. This phenomenon exposes the vulnerability of current GPU architectures when subjected to sustained, high-intensity computations.
Notably, the GPU memory subsystem (including HBM3 and SRAM) became a major failure point, collectively responsible for 21.7% of interruptions. This underscores the critical role of high-bandwidth, large-capacity memory in AI training while exposing the limitations of existing memory technologies in terms of reliability.
To address these challenges, several innovative approaches are necessary:
- Develop more robust GPU architectures optimized for prolonged high-load operations, potentially incorporating advanced error-correction and self-healing mechanisms.
- Redesign memory systems to enhance HBM and SRAM reliability, possibly introducing novel redundancy mechanisms or adaptive error correction techniques.
- Implement advanced cooling solutions, such as two-phase immersion cooling or on-chip microfluidic cooling, to manage the thermal envelope more effectively.
- Explore heterogeneous computing architectures that can dynamically offload computations to specialized accelerators, reducing stress on individual components.
Software Stack: Navigating Complexity and Fragility
Software-related issues, accounting for 12.9% of interruptions, reflect the intricate nature of distributed training system software stacks. To mitigate these challenges:
- Enhance distributed training frameworks with advanced fault-tolerance capabilities, incorporating intelligent checkpointing mechanisms and adaptive failure recovery strategies.
- Develop specialized debugging and performance analysis tools for large-scale model training, leveraging AI techniques for anomaly detection and root cause analysis.
- Implement AI-driven optimization of the training process itself, using reinforcement learning to dynamically adjust training parameters, resource allocation, and data parallelism strategies.
- Explore novel approaches to distributed optimization algorithms that are inherently more robust to node failures and network fluctuations.
Network Infrastructure: The Lifeblood of Data Flow
Network issues (8.4% of interruptions) highlight the criticality of high-performance networking in distributed training. Recommendations include:
- Adopt cutting-edge network topologies, such as all-optical switching fabrics or silicon photonics interconnects, to dramatically increase bandwidth and reduce latency.
- Implement AI-driven network monitoring and traffic management systems capable of predictive congestion avoidance and dynamic routing optimization.
- Explore novel data compression techniques specifically designed for gradient and parameter updates in distributed AI training to reduce network load.
System Management: Balancing Availability and Maintenance
Unplanned host maintenance (7.6% of interruptions) underscores the need for sophisticated system management strategies:
- Implement predictive maintenance systems leveraging machine learning algorithms to forecast potential hardware failures and optimize maintenance schedules.
- Design more flexible training architectures that allow for rolling maintenance without interrupting the overall training process, possibly through advanced model parallelism techniques.
- Develop AI-assisted system administration tools that can autonomously manage large-scale clusters, optimizing resource allocation and minimizing human intervention.
Future Horizons: Towards More Resilient AI Training Infrastructure
The Llama 3.1 405B training experience points to several key directions for future research:
- Develop hardware specifically optimized for AI workloads, potentially rethinking design from the chip to the system level. This could include neuromorphic computing elements or quantum-inspired machine learning processors.
- Construct more intelligent, self-adaptive training systems capable of real-time response and adjustment to various failure scenarios, leveraging meta-learning techniques to optimize system-level parameters.
- Explore new parallelization and distributed training algorithms to enhance system fault tolerance and overall efficiency, such as asynchronous gossip-based training or federated learning approaches adapted for data center environments.
- Investigate the potential of “self-healing” AI systems that can dynamically reconfigure their architecture and training strategy in response to failures or performance bottlenecks.
The pre-training process of Llama 3.1 405B not only pushed the boundaries of language models but also provided invaluable system-level insights. As AI models continue to grow, overcoming these technical challenges will be crucial in driving the next wave of AI breakthroughs. Through hardware innovation, software optimization, and system-level redesign, we can aspire to build more reliable and efficient AI training infrastructure, paving the way for even larger-scale AI models in the future.
The lessons learned from Llama 3.1 405B pre-training underscore the interdisciplinary nature of advancing AI infrastructure. It calls for a collaborative effort among hardware engineers, software developers, network specialists, and AI researchers to holistically address the challenges of extreme-scale AI training. As we stand on the cusp of the next AI revolution, the resilience and efficiency of our training infrastructure will play a pivotal role in shaping the future of artificial intelligence.