Introduction
Recent advancements in artificial intelligence have led to significant improvements in Large Language Models (LLMs). However, these models often struggle with errors, hallucinations, and inconsistencies when performing complex, multi-step inference tasks. To address these challenges, researchers from Skywork AI and Nanyang Technological University have proposed a novel framework called Q* (Q-star). This article examines the Q* framework, a versatile and agile approach designed to enhance machine learning’s multi-step reasoning capabilities, enabling LLMs to achieve deliberative planning abilities.
The Q* Framework: An Overview
The Q* framework, introduced by the Skywork AI and Nanyang Technological University research team, aims to address the limitations of LLMs in multi-step reasoning. This innovative approach incorporates a learned Q-value model as a heuristic function to guide LLMs in selecting the most appropriate next actions without requiring task-specific fine-tuning. The researchers’ goal was to create a general, agile framework that could improve machine learning’s multi-step reasoning capabilities across various tasks.
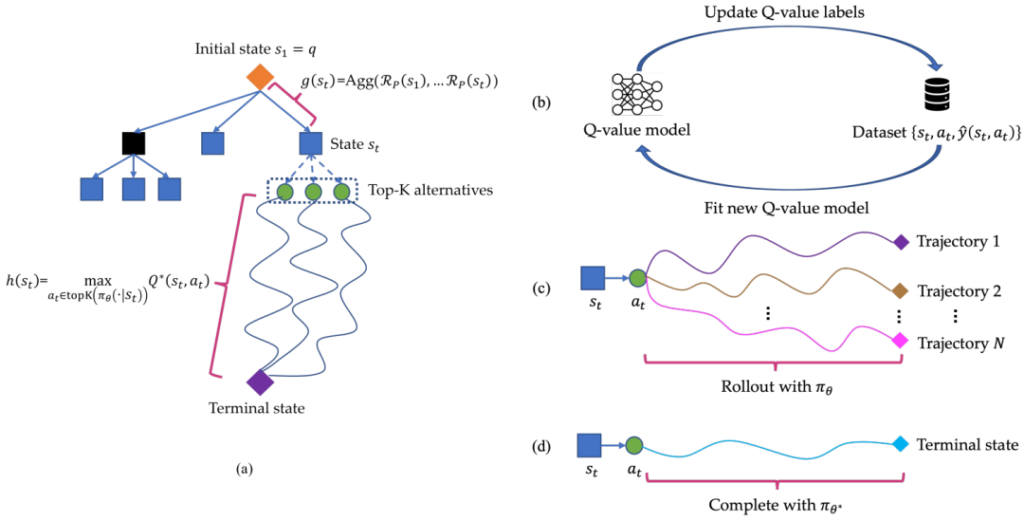
The image above, provided in the original paper, illustrates the key components of the Q* framework:
(a) The search process, including the initial state, state transitions, and terminal state.
(b) The Q-value model and dataset interaction.
(c) Multiple trajectories generated during the rollout process.
(d) A complete trajectory from initial to terminal state.
Key Components of Q*
The Skywork AI and Nanyang Technological University researchers designed the Q* framework with several crucial components:
- Heuristic Search Process: The framework frames the task of finding the most suitable reasoning sequence as a heuristic search process.
- Process-based Reward Function: The researchers implemented a process-based reward function that encodes prior knowledge or preferences for the reasoning task.
- Q-value Model: The framework employs a proxy Q-value model as the heuristic function, guiding the LLM to choose the most promising next steps among the top-K alternatives.
- Best-First Search Algorithm: The researchers implemented a best-first search algorithm using the learned Q-value model to navigate the search space effectively.
Methods for Obtaining Optimal Q-values
The paper outlines three approaches proposed by the Skywork AI and Nanyang Technological University team to obtain optimal Q-values:
- Offline Reinforcement Learning
- Rollout-based Learning
- Utilizing Stronger LLMs
Algorithm Implementation
The researchers implemented the Q* framework using a deliberative planning algorithm, as shown in the pseudocode below:

This algorithm outlines the process of deliberative planning for LLMs using the Q* framework. It takes as input a question q, an LLM policy π_θ, and a proxy Q-value model Q̂.
Experimental Results
The Skywork AI and Nanyang Technological University team evaluated the Q* framework on three datasets: GSM8K, MATH, and MBPP, covering mathematical reasoning and code generation tasks. Their results demonstrate improvements in LLMs’ performance on multi-step reasoning tasks.
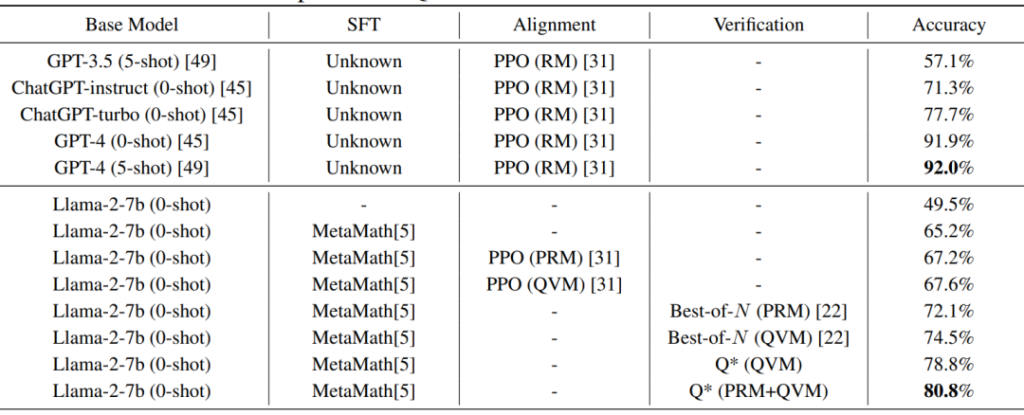
The table above, from the original paper, shows the performance comparison of various models and approaches, including the Q* framework, on different tasks. Key findings include:
- The base model used was Llama-2-7b.
- Several variations of the Q* approach were tested, including Q* (QVM) and Q* (PRM+QVM).
- The Q* (PRM+QVM) approach achieved an accuracy of 80.8% on the tested dataset for the Llama-2-7b model.
- The results also show comparisons with other models and methods.
These results suggest that the Q* framework, particularly the Q* (PRM+QVM) variant, could potentially enhance the performance of LLMs on complex reasoning tasks. However, it’s important to note that these results are specific to the tested datasets and model.
Potential Future Directions
Based on the Q* framework proposed by the Skywork AI and Nanyang Technological University researchers, several potential future research directions can be identified:
- Advanced Heuristic Functions: Exploring more sophisticated heuristics or adaptive heuristics.
- Meta-Learning for Q-value Models: Developing meta-learning approaches for rapid adaptation to new tasks.
- Hierarchical Deliberative Planning: Exploring hierarchical planning structures for more complex tasks.
- Improved Process-based Reward Functions: Developing more sophisticated reward functions.
- Integration with Symbolic AI: Exploring hybrid approaches that integrate neural and symbolic methods.
- Extending to Multi-modal Reasoning: Applying Q*-like approaches to tasks involving both language and visual reasoning.
- Scalable Q-value Estimation: Developing efficient methods for Q-value estimation in very large state spaces.
- Explainable Deliberative Planning: Enhancing the explainability of the deliberative planning process.
- Dynamic Top-K Selection: Exploring adaptive methods for selecting the number of alternative actions to consider.
- Continual Learning in Q-value Models: Investigating how Q-value models can continually learn and improve over time.
These potential directions stem from the core concepts introduced in the Q* framework and represent areas where further research could enhance LLMs’ capabilities in deliberative planning and multi-step reasoning tasks.
Conclusion
The Q* framework, proposed by researchers from Skywork AI and Nanyang Technological University, represents a potentially significant approach to enhancing the deliberative planning capabilities of Large Language Models. By combining heuristic search techniques with the generative power of LLMs, it opens new avenues for research into creating more robust, efficient, and versatile AI systems capable of complex, multi-step reasoning.
While the initial results are promising, it’s crucial to note that these are early findings based on specific datasets and models. More extensive research would be needed to fully validate the effectiveness and applicability of this approach across different models, task domains, and datasets.
The Q* framework and its potential future developments represent an exciting direction in AI research, promising to enhance the deliberative planning capabilities of LLMs. As research in this area progresses, it will be crucial to continue exploring ways to make these advanced AI systems more robust, interpretable, and aligned with human reasoning processes.